
In Part 1, we explored how large language models (LLMs) transform messy internet text into clean, tokenized sequences. But what happens next? How do those tokens become the fluent answers we see from models like ChatGPT, Claude, or Gemini?
The answer lies in neural networks — the engines that turn sequences of tokens into predictions of the next word. In this article, we’ll break down how training works inside an LLM, from tokens to parameters, and why scale is everything.
From Tokens to Training Data
Once text has been tokenized (compressed into IDs using methods like Byte Pair Encoding), the model no longer sees “words” in the traditional sense. Instead, it sees sequences of numbers:
“Hello world” : [15339, 1917]
These token IDs are the input to the model. During training, the network learns to predict the next token in a sequence, given the previous ones.
This framing is what makes LLMs so powerful: they are essentially next-token prediction machines trained at web scale.
Sliding Windows: How Models See Text
Because sequences can be infinitely long, LLMs use a fixed-length context window.
GPT-3 had a window of 2,048 tokens.
Modern models like GPT-4 and Claude 3.5 support windows of 128k+ tokens.
Within this window, the model processes tokens in parallel using a Transformer architecture. Each token attends to others via self-attention, building context dynamically.
Neural Networks at Work
At the core, training involves two key steps:
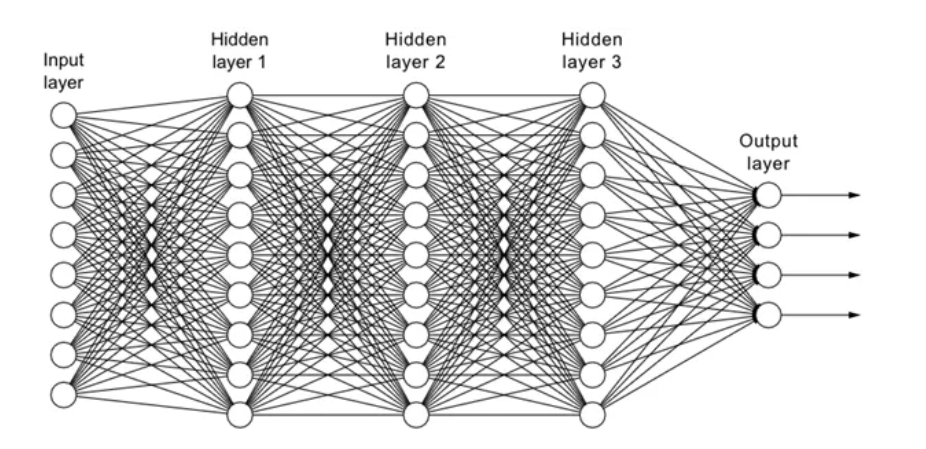
Embedding Layer
Each token ID is mapped to a dense vector representation.
Example:
ID 15339 : [0.25, -0.61, 0.73, …]
These embeddings capture semantic meaning.
Transformer Blocks
Self-Attention : allows tokens to “look at” each other and weigh relevance.
Feedforward Layers : transform information into richer representations.
Residual Connections & Layer Norm : stabilize deep training.
Output Layer
The final layer produces a probability distribution over the vocabulary.
Example:
Next token probabilities: [“world”=0.72, “there”=0.14, “friend”=0.06, …]
The predicted token with the highest probability is chosen (or sampled), and the process repeats.
Training Objective: Next Token Prediction
LLMs are trained with a causal language modeling objective:
Given context [w1, w2, w3 …. wn], predict wn+1.
The model computes a probability distribution for each possible next token.
The training loss measures how far off the prediction is from the actual token.
This is done billions (or even trillions) of times across massive datasets, gradually shaping the model’s ability to predict text patterns.
Scale: Parameters and Compute
Modern LLMs are defined by their scale:
Parameters : GPT-3 had 175B, GPT-4 is estimated in the hundreds of billions. ( GPT-4 is estimated to have roughly 1.8 trillion parameters. More specifically, the architecture consisted of eight models, with each internal model made up of 220 billion parameters.)
Training Data : trillions of tokens, filtered from web-scale crawls.
Compute : training often requires thousands of GPUs for weeks or months. (GPT-4’s foundational model pre-training took approximately three months using thousands of GPUs, such as 8,000 NVIDIA H100 GPUs or their equivalent in older A100 GPUs. The exact training time can vary depending on the hardware used and the specific version of the model, but this general timeframe of about 90 to 100 days is consistent across different reports.)
The combination of parameters, data, and compute is what gives rise to emergent abilities like reasoning, coding, and multi-step planning.
Why Next-Token Prediction Works
At first glance, predicting the “next word” may seem trivial. But at scale, it forces the model to:
Capture semantics (knowing that “king” relates to “queen”).
Model context (understanding that “bank” in a financial article differs from “river bank”).
Learn long-range dependencies (keeping track of entities across paragraphs).
What emerges is not just autocomplete, but a statistical engine capable of mimicking understanding.
Key Takeaways
Token IDs are the fundamental input to LLMs.
Training is about predicting the next token, billions of times.
Transformers enable context modeling through self-attention.
Scale in parameters, data, and compute is the secret behind modern performance.
Closing Thoughts
Large language models don’t start out “knowing” language. They learn it step by step by guessing the next word over and over again, refining billions of parameters until patterns of meaning emerge.
")

")







